A computer clearly has to be able to deal with "text" as well as "numbers", if we are going to use it for general purpose information processing. We need to be able to print out headings, or textual prompts at the very least. More generally, we want to be able to carry out "processing" on textual information: sorting, searching, formatting etc.
Text is ultimately made up of basic components we call characters.
But what exactly counts as a "character"?
In the English speaking world we tend to be happy with upper and lower case alphabetics, some digits, and a selection of miscellaneous brackets, punctuation, and other "special" characters. Even that still leaves room for tremendous variety in style and
But to handle text in most languages of the European Union we need to add a large variety of accented characters (á, ü) etc.; and if we move further afield, things get even more complicated: in the middle East we need arabic and hebrew alphabets, in the CIS we need (at least) the cyrillic character set, and in the far East we need even more elaborate character sets to handle Japanese, the various kinds of Chinese, and so on.
Further, if we want to deal with mathematical notation, we
need to be able to deal with things like sub- and super-scripts
(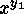 ), and so forth.
), and so forth.
So what should count as a "character", or even how many "distinct" characters we might want to deal with, is a fairly difficult question to deal with.
However, we have to start somewhere!
In the case of computers, the start was historically based on good old fashioned typewriters, or, more strictly, teletypewriters. Teletypewriters, or teletypes, were automatic electric typewriters which could be remotely hooked together, so that whatever was typed on one was automatically printed on the other also. In the early days of computers, teletype machines were already fairly freely available, and were a convenient mechanism for both keying input information into a computer, and for printing output information from the computer.
However, it was in the nature of teletype technology that they could only support a rather limited range of characters: typically just the upper and lower case roman alphabet, digits 0 to 9, and a variety of "special" characters. Furthermore, if these devices were to work properly with each other it was essential that they all adhere to some single standard - both for the characters to be supported, and the way they should be encoded (something akin to the "dots" and "dashes" of the earlier Morse code).
A set of just 96 such characters, plus 32 non-printable "control" characters, together with a standardised way of encoding these into electrical impulses (as strings of "highs" and "lows", or "ones" and "zeros" - i.e. binary numbers) was therefore devised, and became a de facto standard, known as the American Standard Code for Information Interchange, or ASCII for short.
Because it only allows 96 characters, based on the roman alphabet, ASCII is very limited. It doesn't include any accented characters, or even the £ sign. It doesn't allow for variations in size, or style. It can't deal properly with mathematical notation. And it does not address non-roman alphabets at all.
Nonetheless, ASCII has become a sort of "lowest common denominator" or lingua franca of computers. They can virtually all deal with ASCII encoded text.
In particular, the text that makes up computer programs is normally limited to the ASCII character set (or some even more restrictive character set), to ensure that the programs can be potentially processed on the widest possible variety of computers.
Now, the ASCII code is certainly not the only way
of representing textual material in computers, and the standard
for the C language does not absolutely require either that the
characters making up a C program, or the characters making up
textual material being processed by the program, must be encoded
in ASCII. Instead, the standard simply stipulates certain
restrictions on the encoding, which are summarised by
Alcock.![]() ASCII text satisfies these restrictions, and also has some
additional properties which Alcock notes.
ASCII text satisfies these restrictions, and also has some
additional properties which Alcock notes.
As it happens, in the implementation of the C language which you will be using, characters are, indeed, encoded in ASCII and these properties do hold. However, the point to be made here is that in general, in your programs, you should not rely on these latter properties (specific to the ASCII coding), since they are not guaranteed to hold on all computers implementing the C language - except, of course, where your program is specifically intended only to work with ASCII encoded text.