 6 Conclusion
6 Conclusion
 Computational Autopoiesis: The Original Algorithm
Computational Autopoiesis: The Original Algorithm
 4.2 Algorithm
4.2 Algorithm
This section is concerned with comparing the detailed algorithm, as presented in the previous section, with the specific experimental runs documented in (Varela et al. 1974). This comparison reveals a number of discrepancies.
The original paper presents diagrams of two sequences of configurations of the space in the computer model, both taken from a single run, and show ``instants'' 0-6 and 44-47 respectively (figures 1 and 2 of the original). These figures are described as ``... drawn from the print-outs with change of symbols used in the computations''. They use an alternative (iconic) set of symbols for the various types of particles. I have redrawn these figures again, this time substituting the same (alphanumeric) symbols as used consistently throughout the rest of the original paper, and in this report. I have also added numeric co-ordinates along two sides of each diagram of the configuration of the space (to facilitate reference to individual cells or particles), and running counts of the numbers of L particles and holes in the space (which should be always equal, according to the described reaction scheme). My figures 5 and 6 correspond to the original figure 1; my figure 7 corresponds to the original figure 2.
Varela et al. refer to the separate configurations shown as ``successive instants''. I presume this is equivalent to single iterations of the algorithm, or ``timesteps''. This is consistent with EXP29.FOR, but will be discussed further below.
The first sequence (steps 0-6, my figures 5 and 6) illustrates the initial, spontaneous, formation of a structure consisting of a closed chain of L particles enclosing a K particle and also some free L and substrate particles. The second sequence (steps 44-47) illustrates the spontaneous rupturing and repair of the bounding chain. It is stated that ``...[w]ithin this universe these systems satisfy the autopoietic organisation''.
Various problems arise in reconciling these experimental data with the given algorithm.
(Note that the diagrams are inserted here as thumbnail images simply to reduce initial download time; click on the thumbnail to retrieve the full size image.)
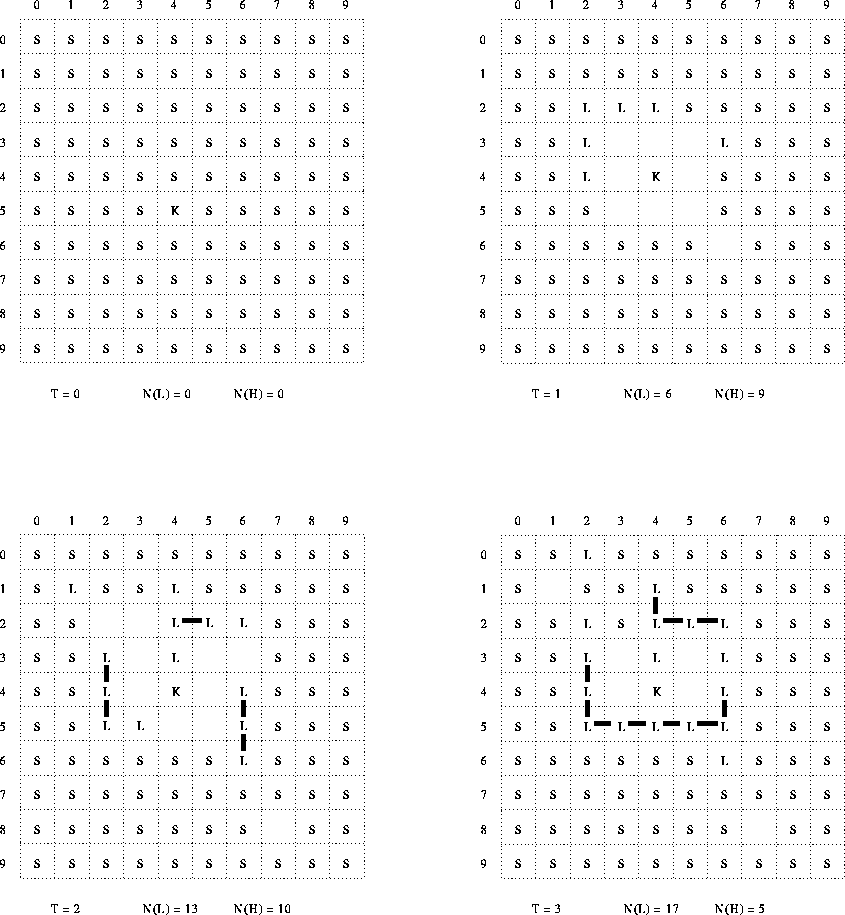
Figure 5: Experimental run: steps 0-3.
The given reaction scheme has two S particles
being required to generate one L particle; and
one L particle disintegrating into two S
particles. On the experimental run the space is
initially configured with one K particle and is
otherwise filled with S particles (T=0). Each
production event should generate one L particle
and one hole, removing two S particles; and each
disintegration event should generate two S
particles, removing one L particle and one hole.
It follows that the number of L particles
(N(L)) should always equal the number of holes
(N(H)). However, in the diagrams shown, this is
never the case (except, of course, for T=0).
For most of the time, the number of L particles
exceeds the number of holes by about 6:1. This is a
gross discrepancy, which is not dependent on any fine
details of the algorithm, and is difficult to
explain. It is conceivable that the diagrams are
showing only a window onto a larger space (such as the
![]() space used in EXP29.FOR),
and that the extra holes have migrated out of the
area shown. However, this interpretation would face
a special additional difficulty with timestep T =
1. At this time the number of holes exceeds
the number of L particles, and, further, there
has not been time for any significant interaction
from the boundaries of the area shown. I can see no
consistent and reasonable way of fully reconciling these
variations in the ratio between N(L) and N(K)
with the specified reaction scheme.
space used in EXP29.FOR),
and that the extra holes have migrated out of the
area shown. However, this interpretation would face
a special additional difficulty with timestep T =
1. At this time the number of holes exceeds
the number of L particles, and, further, there
has not been time for any significant interaction
from the boundaries of the area shown. I can see no
consistent and reasonable way of fully reconciling these
variations in the ratio between N(L) and N(K)
with the specified reaction scheme.
The algorithm restricts production to a rate of one L particle per timestep per K particle. Yet, in the experimental run, we apparently observe production of six L particles (by the one available K particle) in going from T=0 to T=1. Similarly, from T=1 to T=2 we see the number of L particles increasing to 13, implying production of at least a further 7 L particles in that step. Similar, though somewhat less dramatic, discrepancies occur between T=2 and T=3, and between T=4 and T=5. Even on those steps where the reaction rate is not apparently excessive, it seems likely that this is due only to limited availability of S particles in the vicinity of the K particle.

Figure 6: Experimental run: steps 4-7.
A conceivable interpretation of this is that the time ``instants'' in the diagram correspond to multiple iterations of the algorithm (time ``steps''). However, there is no evidence in the discussion of the paper that would support this. Further, it would not be consistent with the fact that, at T=1, none of the produced L particles are yet bonded.
Even if we suppose that multiple production events might be allowed per K particle per timestep, there are additional, subsidiary, peculiarities of the configuration at T=1. First, the production reaction requires two S particles adjacent to the K particle. Thus, to produce six L particles would require twelve S particles--but there are, at most, only eight positions immediately adjacent to the K. Furthermore, the spatial distribution of the produced L particles seems strange. None of the produced particles at T=1 are immediately adjacent to the K particle--even though the production reaction specifies that a newly produced L is always adjacent to the K.[13] Finally, of the six produced L particles, five are immediately adjacent to each other--which would seem very unlikely if the choice of reaction sites, in the vicinity of the K particle, were stochastic.
However: it turns out that EXP29.FOR yields almost exactly the same pattern of initial production as illustrated at T=1 and an examination of its code reveals answers to all the discrepancies noted here.
Firstly, EXP29.FOR does not restrict production to just one event per K particle per timestep, but actually permits up to one event per (Moore) neighbor of a K particle per timestep--which is to say, up to 8 production events per catalyst per timestep.
Secondly, for each Moore neighbor of a K particle, if that neighbor is an S particle, EXP29.FOR searches in the Moore neighborhood of that S particle in turn, seeking a second S particle for the production reaction. Thus, while the two reacting S particles must be adjacent to each other, only one of them need be adjacent to the mediating K particle. This effectively increases the neighborhood for the production reaction to two positions away from the K particle, an area of size 25. This greatly increases the availability of potential reactants. It also introduces the possibility that the produced L will actually be two positions away from the K particle (even before any movement).
Finally, in EXP29.FOR, the searching for reactants, and the selection of which to replace by a L particle, is deterministic. This fully accounts for the systematic bias of the initial production to the Northwest of, and two positions away from, the K particle.
In the course of the times T=0 through T=6, the K particle moves just once. In the times T=44 through T=47 it does not move at all--and, indeed, is still in the same position as at times T=1 through T=6. This is not consistent with the algorithm (top-level step 3) which should force the K particle to move virtually every timestep (its maximum ``mass'' meaning that it can displace, or at worst, swap with, any other kind of particle).
It might be conjectured that, in redrawing the diagrams, the authors simply recentered on the K particle each time. However, this idea is not consistent with the fact that the K particle does move once; and, more substantively, it is not consistent with the fact that the bonded L particles, which are specified to remain absolutely immobile in the space, do not change their positions relative to the K particle.
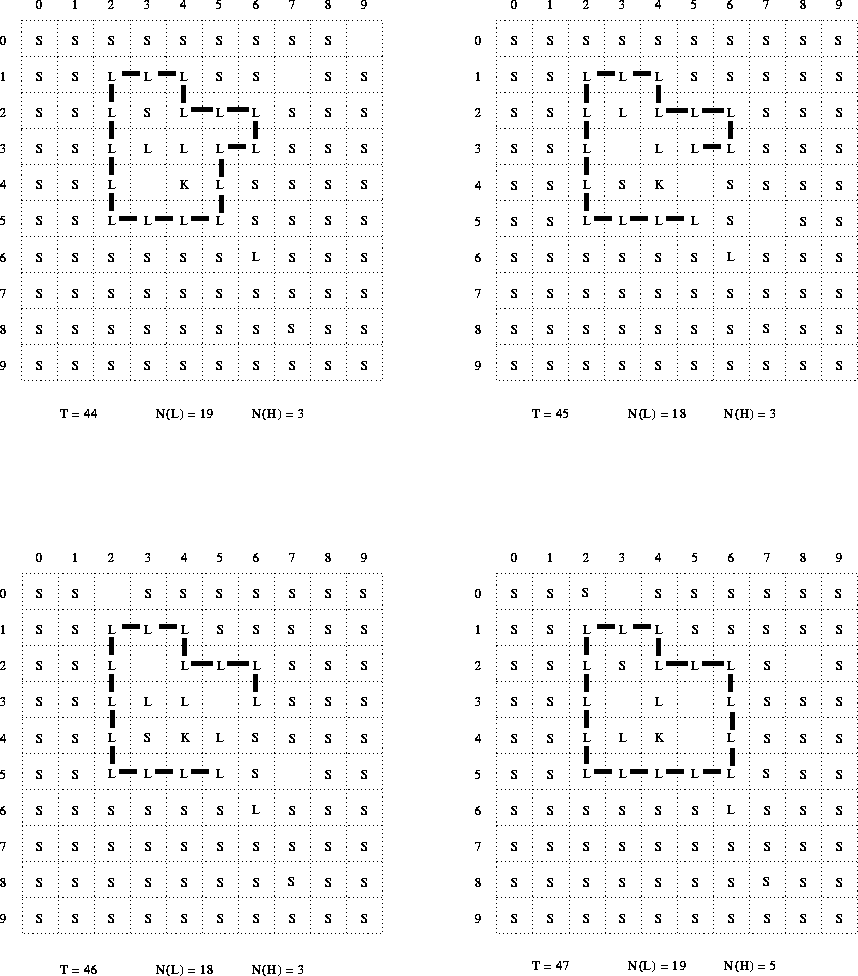
Figure 7: Experimental run: steps 44-47.
The algorithm stipulates that bond angles less than
![]() are to be disallowed. The diagram
illustrating this (figure 4 of the original, redrawn
as figure 2 here) shows a bond angle of
are to be disallowed. The diagram
illustrating this (figure 4 of the original, redrawn
as figure 2 here) shows a bond angle of
![]() . This clearly suggests that, in general,
bonding is to be allowed along diagonals of the
space, except only in the case where that would
result in a bond angle of less than
. This clearly suggests that, in general,
bonding is to be allowed along diagonals of the
space, except only in the case where that would
result in a bond angle of less than ![]() . Yet,
in all the experimental configurations shown, all
bonds occur only in the orthogonal directions, never
in the diagonal directions. Clearly, the possibility
of diagonal bonding would have a significant effect
on the shapes of L particle chains which may
form, and may thus significantly affect the dynamics
of any autopoietic organisation which the model might
support.
. Yet,
in all the experimental configurations shown, all
bonds occur only in the orthogonal directions, never
in the diagonal directions. Clearly, the possibility
of diagonal bonding would have a significant effect
on the shapes of L particle chains which may
form, and may thus significantly affect the dynamics
of any autopoietic organisation which the model might
support.
Again, the EXP29.FOR code may shed some light on the this. In that program, bonds are not explicitly represented or displayed, though they may be said to be implicitly encoded in the transformation and movement processes. If the diagrams of (Varela et al. 1974) derive from a closely related program, then, in redrawing the diagrams from the original printouts, the drawing of explicit bonds would have been at best schematic, or suggestive, rather than reflecting definite operations of the program.
As already discussed at length, the published algorithm makes provision for bonding to occur several different times within each iteration. In particular, every time a free L particle is produced or moves, it is supposed to be considered for bonding. Considering now the experimental configuration at T=1 we have (apparently) six L particles, all of which have just been produced, and five of which are adjacent to each other. If the bonding procedure (top-level step 6) were applied to the latter five particles then they would all have become bonded. Yet no bonds are shown between any of them. This is the most dramatic discrepancy with regard to the bonding algorithm--but there are other instances also.
In particular, consider the transition from T=46 to T=47. A free L particle apparently moves from position (3,2) to position (3,3), where it becomes immediately adjacent to another free L at position (4,3)--yet no bond is formed between them.
This is extremely significant, as the formation of such bonds--between free L particles enclosed within the ``membrane''--would prevent such particles being available to migrate to a rupture site. The possibility of such reactions would thus appear to undermine a critical aspect of the claimed autopoietic organisation.
Note that this discrepancy is not a stochastic or probabilistic one: the algorithm as given makes bonding effectively deterministic where possible, (the only stochastic element arises in choosing between multiple available bonding configurations, not in deciding whether bonds should form at all). Thus, it does not seem plausible that, in the given experimental configurations, it simply ``chanced'' that certain L particles did not bond to each other.
However, we again find that, if the program in use was closely related to the EXP29.FOR code (rather than the algorithm as stated) this may provide some explanation.
Firstly, the overall algorithm of EXP29.FOR involves scanning the space in a systematic, West to East, then North to South, raster pattern. There are several such scans per timestep; but production and bonding are implemented in the same scan. This happens to interact with the deterministic pattern of production events in just such a way that all but one of the initially produced L particles appear in positions that have already been processed in that scan. Thus they are not processed for bonding until the second timestep.[14]
Secondly, EXP29.FOR implements some special constraints on bonding. While I have not been able to fully decipher the intentions here, I have been able to explicitly identify some of these constraints. The most crucial seems to be that on bonding of a free L particle, and appears at lines 232-3 of the listing. The effect of this is that a free L particle can form a bond only if there is no more than one doubly-bonded L particle in its immediate (Moore) neighborhood. In effect, this tends to inhibit the formation of bonds by free L particles that are immediately adjacent to an existing chain of L particles. It establishes a sort of bond inhibition ``field'' around such a chain. In particular, it is a mechanism to prevent free L particles, produced inside a membrane formed by the closure of such a chain, from bonding to each other (provided, of course that the space inside is not too large).
Clearly, this can explain the otherwise puzzling lack of bond formation between T=46 and T=47, already discussed. More importantly, it provides a possible mechanism to ensure the continued mobility of the L particles trapped inside the membrane, and thus their continued availability to migrate to a rupture site. This certainly appears to be a very important mechanism in the attainment of the desired autopoietic closure. Yet, there is no hint of such a mechanism either in (Varela et al. 1974), nor even in the contemporary descriptive account of PROTOBIO. This suggests to me the possibility that, at the time of writing the paper, the authors themselves may no longer have been fully aware of all the interactions (or their significance) coded into the model.
We have seen how a number of the most puzzling discrepancies between the experimental results and the algorithm of (Varela et al. 1974) can be explained by assuming that the diagrams were produced by a program at least closely related to that of EXP29.FOR. However, a corollary of this is that the algorithm implemented by EXP29.FOR is indeed significantly different from that actually described in (Varela et al. 1974). This suggests the possibility that the illustrated experimental results may have derived from a relatively early version of the model (i.e. closely related to EXP29.FOR), while the algorithm may date from a much later (more complex and/or sophisticated) version. It is impossible to determine this more exactly, so long after the event. However, in support of this conjecture, I may note that Varela's own published account (Varela 1996) explains that this work was done under very complex and volatile circumstances in Chile, shortly before the violent overthrow of the Allende government. Furthermore, there was a substantial delay between the original work and the preparation of the final published manuscript. Taken together, it seems to me that these factors could reasonably explain an accidental (albeit substantial) version mismatch between the published algorithm and the experimental results.
6 Conclusion
Computational Autopoiesis: The Original Algorithm
4.2 Algorithm
Copyright © 1997 All Rights Reserved.
Timestamp: Tue Dec 31 18:43:32 GMT 1996